Testing Espanso and local Llama.cpp for inline AI Text!

I recently set aside several hours to follow a tutorial to play with some AI tools I’ve been eyeing 👀… here are some (shorthand and messy) notes about my journey setting up and utilizing Llama.cpp locally and integrating it with Espanso for seamless (and more private) text generation in any macOS app where you can type things.
Here’s what it looks like end-to-end (type some text anywhere, command-X to cut, trigger Espanso):
Here’s what’s covered below:
- setting up and utilizing Llama.cpp
- a rehash of how I followed this tutorial: Llama.cpp Tutorial: A Complete Guide to Efficient LLM Inference and Implementation
- integrating it with Espanso for text generation.
- Espanso trigger yaml
- python script
The Journey with Llama.cpp
Initial Setup:
Diving into the Llama.cpp tutorial, it guides us through the essentials of setting up the development environment and understanding the core functionalities of Llama.cpp. Concise summary of the steps we followed:
- Environment Setup:
- Installed Conda to manage the Python environment.
- similar workflow to using virtualenv which I was a bit familiar with already.
- Created a Conda virtual environment specifically for Llama.cpp.
- Installed necessary dependencies, including the Llama-cpp-python package.
- only one package had to be installed with
pip(python package manager)
- only one package had to be installed with
- Installed Conda to manage the Python environment.
- Loading and Using Llama Models:
- Loaded the Zephyr-7B-Beta model from Hugging Face. Link: https://huggingface.co/HuggingFaceH4/zephyr-7b-beta (similar to mistralai/Mistral-7B-v0.1 apparently)
- Configured the model with some different parameters such as context size and token limits and removed some “stop” words to get it to run.
- for some reason the tutorial recommends the
\nwhich would stop output too soon for some outputs.
- for some reason the tutorial recommends the
- Implemented the python text generation script using the
Llamaclass/constructor from the Llama-cpp-python package.
Challenges and Debugging:
Throughout the process, I encountered several issues:
- Activating the Conda environment within different contexts (manual vs. automated execution via Espanso).
- At first I tried calling the script from Espanso, but realized the environment needs to be activated every time. I couldn’t figure out a way to “attach” to an existing open bash session that had virtual environment running already (Is that a thing? 🤷♂️).
- Ensuring all dependencies, including Llama-cpp-python, were correctly installed and accessible from both environments.
- Debugging issues related to model path and environment activation, especially when integrating with Espanso.
- Espanso did not like that I was using a relative path for the LLM model for some reason I never figured out.
Integrating with Espanso
What is Espanso?
Espanso is a powerful text expander and snippet manager that allows you to automate text input across applications. Basically you can type a trigger word for example :signature in any app and Espanso will replace the text there. It’s flexible and extensible so you can run local scripts to output text (instead of just static text snippets). By integrating Espanso with Llama.cpp, we aimed to create a seamless workflow where specific triggers could prompt the LLM to generate text based on clipboard content. LLM anywhere you are typing! Cool.
Espanso Configuration:
Here’s a detailed look at how I configured Espanso to work with Llama.cpp:
- Base Configuration:
- Defined a trigger (
:llama) that captures clipboard content. - Used a shell command to activate the Conda environment and run the Python script directly.
- For more details on how to use and configure Espanso to run Shell commands, check out https://espanso.org/docs/matches/extensions/#shell-extension
- Defined a trigger (
# Local LLaMa
- trigger: ":llama"
replace: ""
vars:
- name: "clipboard"
type: "clipboard"
- name: output
type: shell
params:
cmd: "source /Users/daniel.matteson/miniconda3/etc/profile.d/conda.sh && conda activate llama-cpp-env && python /Users/daniel.matteson/Documents/code/llama/llama_cpp_text_generation.py \"\""
shell: zsh
For some simpler example of Espanso triggers, see https://espanso.org/docs/matches/basics/
- Python Script Adjustments:
- Ensured the Python script uses absolute paths for model loading.
- Error handling which will then bubble up to Espanso so I know if something breaks in the LLM layer without having to look at Espanso logs
- Handle command line arguments for the prompt which will come from the Espanso’s user’s clipboard. Don’t copy passwords (🔐)!
- Here is the full script, adapted a little from the tutorial version
import sys
from llama_cpp import Llama
# Check if the prompt is provided
if len(sys.argv) < 2:
print("Usage: python llama_cpp_text_generation.py <prompt>")
sys.exit(1)
# Get the prompt from the command-line arguments
prompt = sys.argv[1]
# Specify the path to the model
model_path = "/Users/daniel.matteson/Documents/code/llama/model/zephyr-7b-beta.Q4_0.gguf"
# Load the model
zephyr_model = Llama(model_path=model_path, n_ctx=512)
# Define the generation parameters
max_tokens = 100
temperature = 0.1
top_p = 0.95
echo = False
stop = [] # Removed "\n" as a stop parameter
# Generate text
try:
model_output = zephyr_model(
prompt=prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop
)
# Extract and print the generated text
if "choices" in model_output and len(model_output["choices"]) > 0:
generated_text = model_output["choices"][0]["text"].strip()
print(generated_text)
else:
print("No generated text found.")
except Exception as e:
print(f"An error occurred: {e}")
Observations and Results:
Using Espanso, we triggered text generation by copying a prompt to the clipboard and typing :llama. The integration worked seamlessly, but we observed that the model’s output could be gibberish without proper prompt engineering. For instance, a simple knock, knock, who's th prompt resulted in mixed, incomplete sentences…
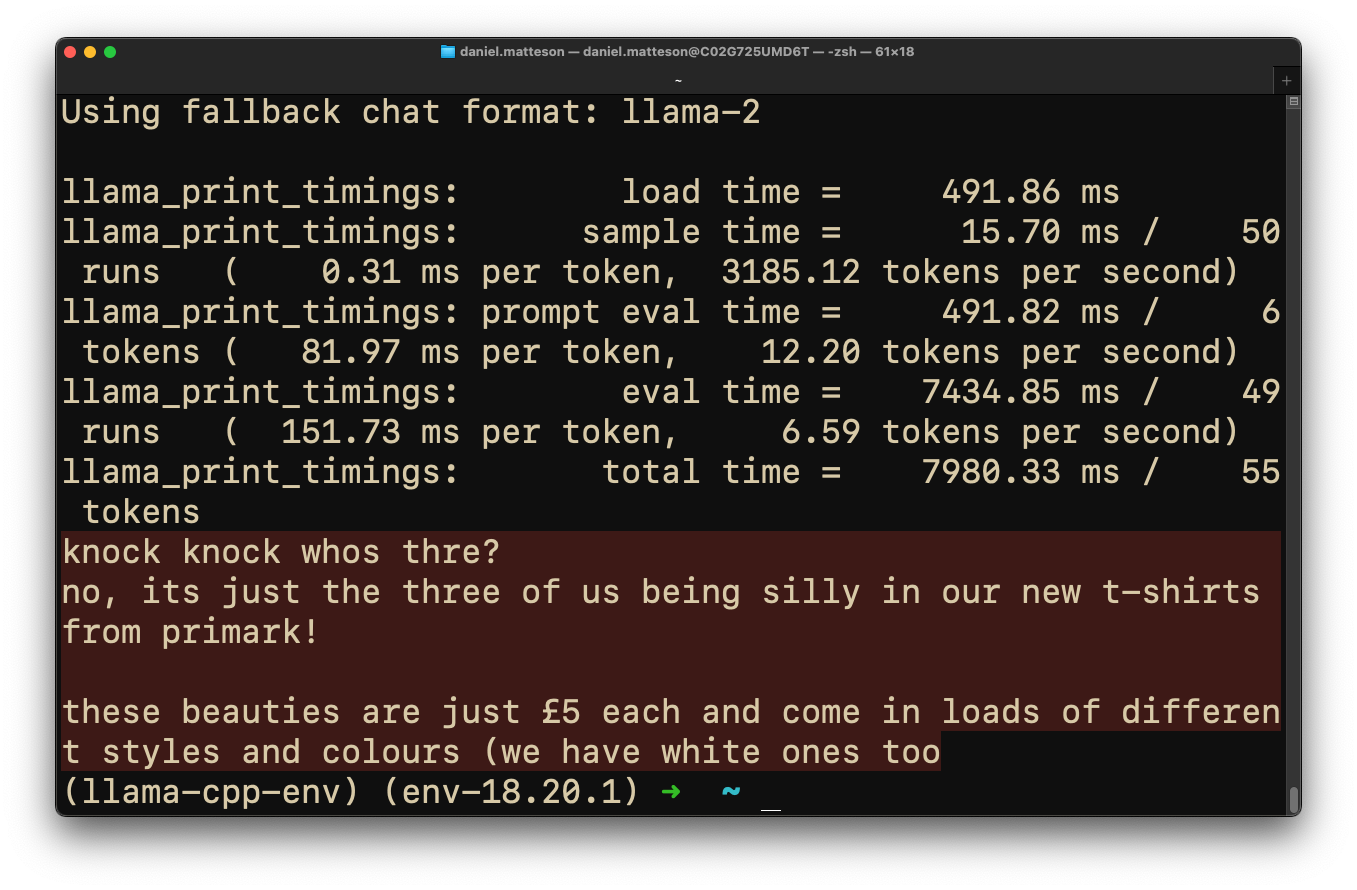
Enhancing LLM Output
To improve the coherence and relevance of the model’s responses, maybe we can craft (engineer?) some prompts that provide clearer context and guidance to the model. Something like this:
Priming Prompt:
We can prepend a priming prompt to the user input that sets the context for the LLM, encouraging it to generate responses in a more conversational and helpful manner.
# Get the prompt from the command-line arguments
prompt = sys.argv[1]
priming_prompt = "System: You are a friendly and knowledgeable assistant. Answer the following query in a helpful manner in 1 sentence and less than 75 words. "
full_prompt = priming_prompt + "User: " + prompt + " Assistant: "
The output for this one is marginally better and more coherent. But more adjustments are needed!
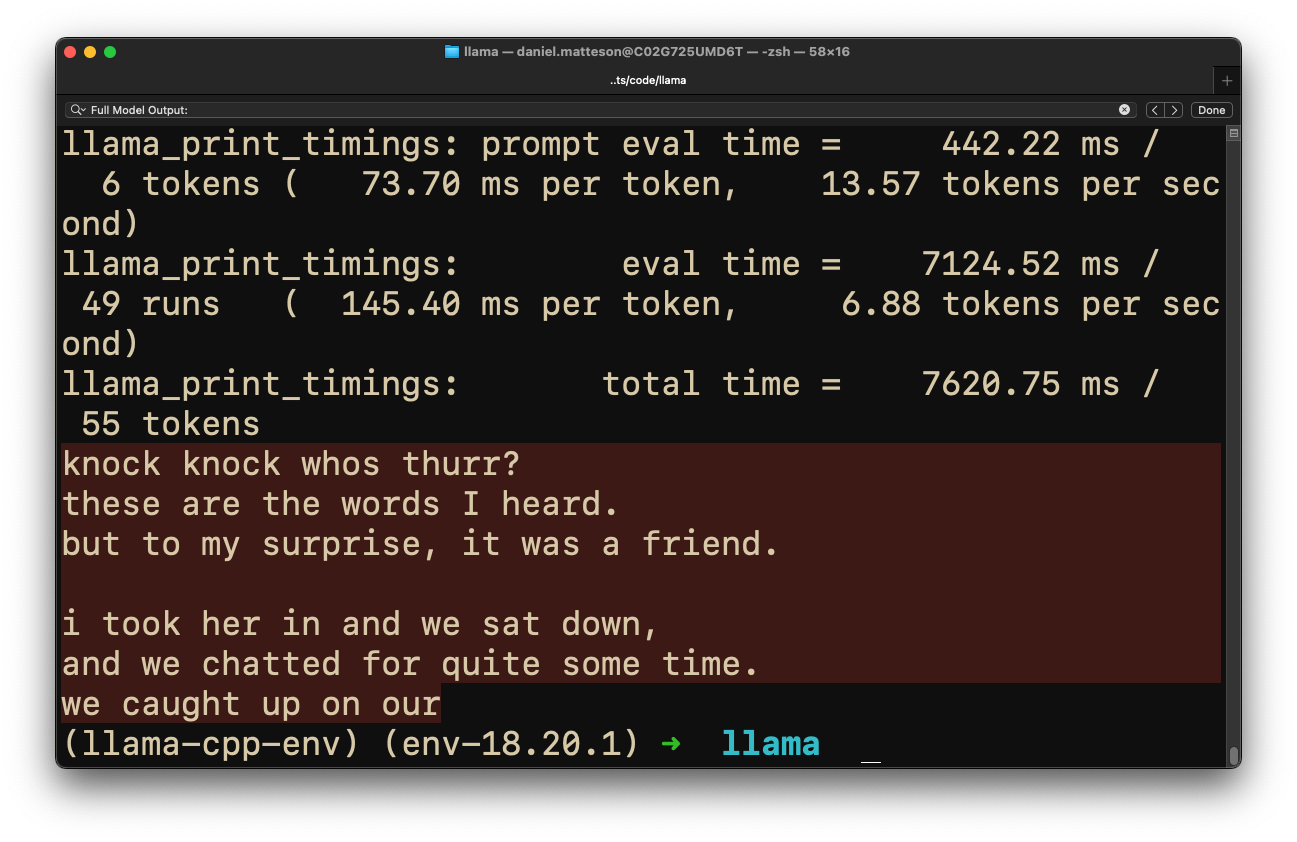
Compare this to a higher quality output from NextChat (OpenAI):

Enhancing Efficiency and Privacy with Local AI Integration
The reason I have Espanso calling a local script is because of a previous “tool” I recreated that used a Node.js script to interact with the Airtable API. This script would run a prompt through an AI field in a private Airtable base, writing the prompt to the AI field and polling the API until the AI-generated text appeared in the field’s cell value. While this method generally produced high-quality outputs thanks to leveraging Airtable’s OpenAI’s GPT-3.5 or GPT-4, it suffered from significant delay due to the network requests involved. And it passed all the data to Airtable and OpenAI.
Replacing the Node.js Airtable API script with a Python script that does everything locally ensures better privacy and security since no data is transmitted over the network or even to any 3rd party! The integration is shows the flexibility of running AI models directly on local hardware BUT it isn’t high quality output yet (because I have no idea what I’m doing quite frankly) without relying on external APIs.
To Wrap Up
Our journey through the Llama.cpp tutorial and integrating it with Espanso was challenging but rewarding. We learned how to set up the environment, integrate the model, and the importance of prompt engineering for coherent outputs… :)
I initially used a Node.js script to run prompts through an AI field in Airtable, but it was slow due to network requests. Switching to a local Python script improved speed and privacy, although the output quality is currently way lower without using OpenAI’s models.
This project showed us how to use LLMs locally and run scripts with Espanso. It was a fun challenge.
Update Jun 24, 2024: Migrating from Espanso to Raycast… Why?
Since my last update, I’ve made changes to my workflow! I’ve switched from using Espanso to Raycast. This transition has streamlined my processes and consolidated multiple tools into one. Raycast is an incredibly versatile tool that not only supports script commands but also replaces several disparate tools I was previously using. It functions as a clipboard manager, window manager, snippet manager, and much more. This all-in-one capability reduces the need for multiple applications, simplifying my workflow and boosting productivity.
Migrating the Code
Migrating the code from Espanso to Raycast was straightforward. I adapted my existing scripts to fit into Raycast’s script command structure. Here’s an example of how I modified my script:
- Initialization and Setup:
- Ensured that Raycast initializes the necessary environment by sourcing the Conda initialization script.
- Activated the specific Conda environment for running the LLaMa model.
- Clipboard Interaction:
- Used
pbpasteto capture clipboard content directly in the Raycast script. (what is pbpaste?)
- Used
- Executing the Python Script:
- Ran the Python script to generate the desired output using LLaMa.
- Suppressed unnecessary diagnostic outputs to reduce the output to just the LLM’s generated text.
- Output to Raycast:
- Echoed the result back to Raycast for easy access and copying.
Here’s the Raycast script that I use:
#!/bin/bash
# Raycast Script Command
#
# This script takes input from the clipboard, invokes a Python script to process it using LLaMa,
# and outputs the result directly in the Raycast interface.
#
# Required parameters:
# @raycast.schemaVersion 1
# @raycast.title LLaMa
# @raycast.mode fullOutput
#
# Optional parameters:
# @raycast.icon 🦙
# @raycast.packageName Raycast Scripts
# Ensure conda is initialized
source ~/miniconda3/etc/profile.d/conda.sh
conda activate llama-cpp-env
# Capture the clipboard content
PROMPT=$(pbpaste)
# Define the path to the Python script
PYTHON_SCRIPT=".../llama/llama_cpp_text_generation.py"
# Run the Python script with the prompt from the clipboard and capture the output, suppressing llama-cpp diagnostic output
OUTPUT=$(.../bin/python "$PYTHON_SCRIPT" "$PROMPT" 2>/dev/null)
# Output the result to Raycast
echo "$OUTPUT"